
An Engineer's Guide to Kafka
By a Fake (AKA Software) Engineer
This guide is based on Understand Kafka as if you had designed it — Part 1 and 2 on Medium:
https://medium.com/towards-data-science/understanding-kafka-as-if-you-had-designed-it-part-1-3f9316cb8fd8
https://towardsdatascience.com/understanding-kafka-as-if-you-had-designed-it-part-2-33d0d24c79f1
The Engineering Loop
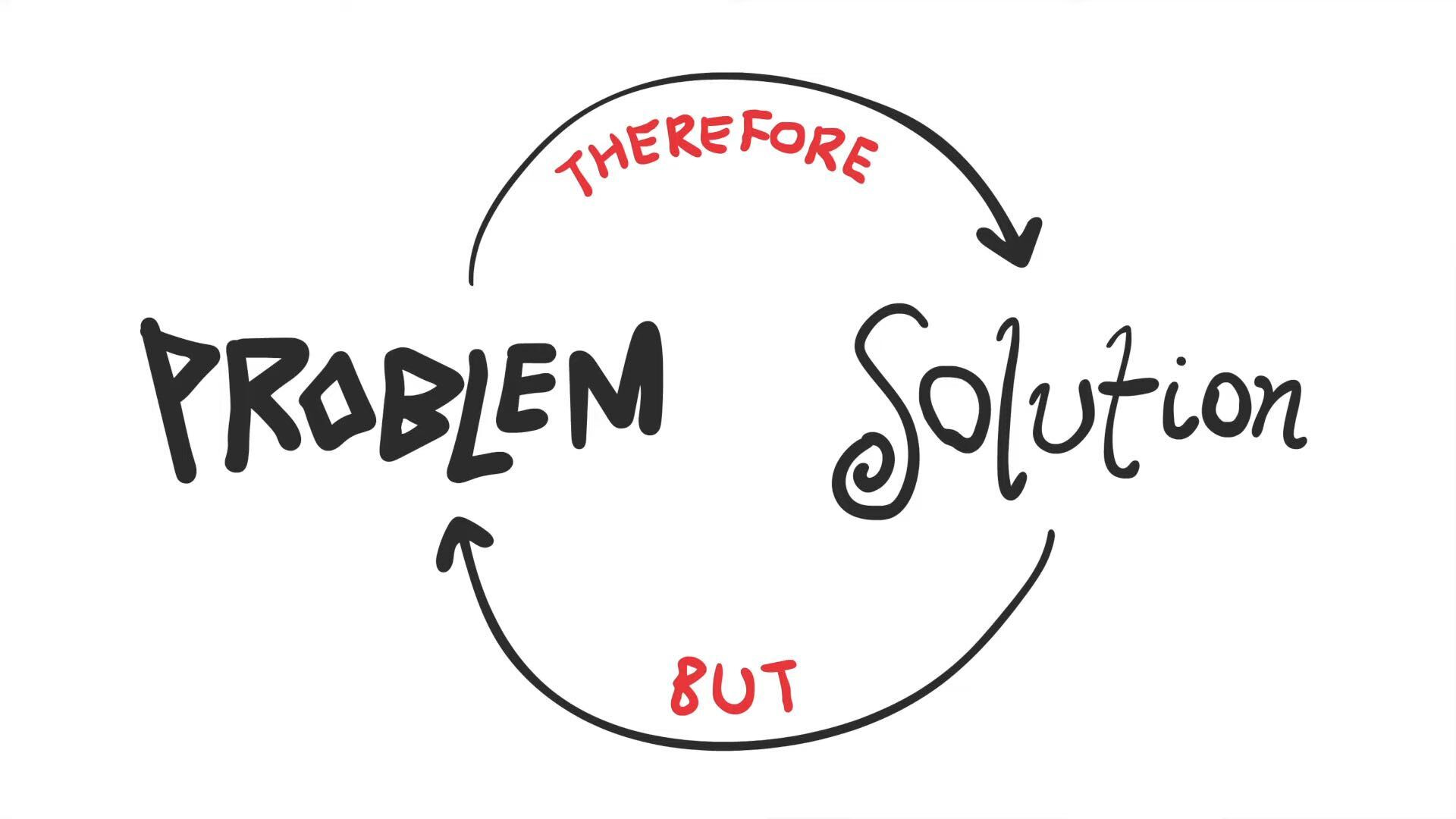
What is the Engineering Loop?
Fundamentally, all innovation/technology/learning comes from this loop:
Problem THEREFORE Solution BUT Problem THEREFORE...
(Watch How To Explain Things Real Good (Stanford mini-talk)
for an absolutely fantastic breakdown of this loop, and learning in general)
Compare the Engineering Loop to Kafka's official introduction: https://kafka.apache.org/intro
Kafka is blah blah blah I'm already bored
Why? Because it's just describing the solution
Why do I care about the solution? What's the problem? We want a fast and scalable systemzzzzzz
I'm not a marketing person, I'm a (fake) engineer
What specific system do I have, and what specific problems?
And is Kafka the best solution to those problems?
(The following descriptions will seem a bit esoteric and overly-long, but the goal is to show the conceptual nut-and-bolts of Kafka, before telling you how Kafka puts them together. Show, then Tell, not the other way around)
1. Why Storage?
I have 1 INSTRUMENT which outputs 1 MEASUREMENT every 5 mins
I have 1 MACHINE which inputs 1 MEASUREMENT at any time and does stuff
I have 1 PLASTIC BIN which stores MEASUREMENTS
How should I connect the INSTRUMENT, MACHINE, and PLASTIC BIN to output stuff?
Trick question, I don't need the PLASTIC BIN. Just connect the INSTRUMENT to the MACHINE
2. Mismatch Between Inputs and Outputs
I have 2 INSTRUMENTS which outputs 1 MEASUREMENT every 5 mins
I have 1 MACHINE which inputs 1 MEASUREMENT every 2 mins and does stuff
I have 1 PLASTIC BIN which stores MEASUREMENTS
How should I connect the INSTRUMENTS, MACHINE, and PLASTIC BIN to output stuff?
What is software engineering but the logistics of data?
And what is logistics but transformations in SPACE, TIME, and FORM?
I have MEASUREMENTS I want to use but cannot now use; I need to transform them in TIME
Problem: I need STORAGE
Therefore: I connect the INSTRUMENTS to the PLASTIC BIN, and the PLASTIC BIN to the MACHINE
(If you haven't figured, the PLASTIC BIN is the RDBMS in this metaphor ;P)
This also decouples the INSTRUMENTS from the MACHINE
If the INSTRUMENTS break, the MACHINE is still able to input MEASUREMENTS from the PLASTIC BIN
I have solved one problem with a many-faced THING, and because the THING has many faces, sometimes by solving one problem with one face, I solve a different problem with another
3. Faster Reads than Writes
I improve the MACHINE so that that it inputs 1 MEASUREMENT every 0.0000001 mins and does stuff
(The system is unchanged, I just don't want to keep track of the polling intervals, lol. What matters is that we read much faster than we write)
4. Different Types of Inputs
I have 1 X INSTRUMENT which outputs 1 X MEASUREMENT every interval
I have 1 Y INSTRUMENT which outputs 1 Y MEASUREMENT every interval
I have 1 MACHINE which inputs 1 X or Y MEASUREMENT and does stuff
I have 1 PLASTIC BIN with an X compartment which can store X MEASUREMENTS
Problem: The PLASTIC BIN can only store X MEASUREMENTS, but I want to store Y MEASUREMENTS
Therefore?: I upgrade the PLASTIC BIN, adding an Y compartment to store Y MEASUREMENTS
But: What if I want to add W and Z INSTRUMENTS later? Or A, B, C...
Constantly adding compartments (schemas) to the PLASTIC BIN seems like a pain
What if instead of having a PLASTIC BIN with neatly organised compartments (schema-on-write), I put all the raw MEASUREMENTS (binary data) into a PILE, and let the MACHINE handle the differences (schema-on-read)?
After all, the MACHINE doesn't care whether the input is an X or Y MEASUREMENT (We don't need to query or filter), so why bother going through all that effort to organise the MEASUREMENTS?
After I input the MEASUREMENT into the MACHINE, I can just throw it away, so I know I won't accidentally input the same MEASUREMENT twice
What could possibly go wrong?
5. Error Handling
Oops, the MACHINE threw an ERROR while processing a MEASUREMENT
Looks like I have to keep the MEASUREMENTS after inputing them into the MACHINE, just in case I need to reprocess them
How do I organise the PILE a little, so that I know if a MEASUREMENT has already been input?
Without going as far as organising everything back into compartments in a PLASTIC BIN
Well, I know that a PLASTIC BIN (RDBMS) is actually organised in two ways:
By compartments (schema)
By a numbered list (index)
I replace the PILE with a NUMBERED LIST (append-only log)
(It's a bit mind-bendy to think of actual, useful data being stored in logs as opposed to fluff text produced by apps as a side-effect, but roll with it)
Each time I put a MEASUREMENT in the NUMBERED LIST, I NUMBER the MEASUREMENT, adding one to the previous NUMBER (offset)
I have a notepad by the MACHINE, which tracks the NUMBER of the last MEASUREMENT that has been input into the MACHINE
By comparing the NUMBER of a MEASUREMENT with the NUMBER of the last MEASUREMENT, I know if a MEASUREMENT has been input into the MACHINE
Side Note 1 - The Magic of TCP
Talking about ERRORS reminded me of this oldie-but-goodie blog post from Joel Spolsky: The Law of Leaky Abstractions
There’s a key piece of magic in the engineering of the Internet which you rely on every single day. It happens in the TCP protocol, one of the fundamental building blocks of the Internet.
TCP is a way to transmit data that is reliable. By this I mean: if you send a message over a network using TCP, it will arrive, and it won’t be garbled or corrupted.
We use TCP for many things like fetching web pages and sending email. The reliability of TCP is why every email arrives in letter-perfect condition. Even if it’s just some dumb spam.
By comparison, there is another method of transmitting data called IP which is unreliable. Nobody promises that your data will arrive, and it might get messed up before it arrives. If you send a bunch of messages with IP, don’t be surprised if only half of them arrive, and some of those are in a different order than the order in which they were sent, and some of them have been replaced by alternate messages, perhaps containing pictures of adorable baby orangutans, or more likely just a lot of unreadable garbage that looks like that spam you get in a foreign language.
Here’s the magic part: TCP is built on top of IP. In other words, TCP is obliged to somehow send data reliably using only an unreliable tool.
To illustrate why this is magic, consider the following morally equivalent, though somewhat ludicrous, scenario from the real world.
Imagine that we had a way of sending actors from Broadway to Hollywood that involved putting them in cars and driving them across the country. Some of these cars crashed, killing the poor actors. Sometimes the actors got drunk on the way and shaved their heads or got nasal tattoos, thus becoming too ugly to work in Hollywood, and frequently the actors arrived in a different order than they had set out, because they all took different routes. Now imagine a new service called Hollywood Express, which delivered actors to Hollywood, guaranteeing that they would (a) arrive (b) in order (c) in perfect condition. The magic part is that Hollywood Express doesn’t have any method of delivering the actors, other than the unreliable method of putting them in cars and driving them across the country. Hollywood Express works by checking that each actor arrives in perfect condition, and, if he doesn’t, calling up the home office and requesting that the actor’s identical twin be sent instead. If the actors arrive in the wrong order Hollywood Express rearranges them. If a large UFO on its way to Area 51 crashes on the highway in Nevada, rendering it impassable, all the actors that went that way are rerouted via Arizona and Hollywood Express doesn’t even tell the movie directors in California what happened. To them, it just looks like the actors are arriving a little bit more slowly than usual, and they never even hear about the UFO crash.
I'm generally very lazy about handling errors (sorry, everyone who has ever had to work with my code!), so this is a nice reminder about how much error handling affects system design
6. Pages
Problem: Each MEASUREMENT is not a single record, written down on a single long sheet of paper of varying lengths but a collection of pages of varying count, not necessarily stapled together, that should be read in a specific order
If I store the pages in a random order, even if I knew where all the pages were, I would have to run around everywhere to gather them together before I can input them into the MACHINE
But the solution of a NUMBERED LIST is a THING with many faces. By solving the problem of knowing whether a MEASUREMENT has been input, I have also solved the problem of what order to store the pages (sequential writes/reads) for maximum efficiency
(Kafka uses disk storage and not RAM because its designed to handle a lot of data/have a high throughput, and RAM is expensive. Compare Kafka to Redis. Redis uses RAM because its designed for caching, so it needs very high speeds/low latency for a small amount of data. Kafka has to do a lot of speed optimisations to make up for using disk storage, and sequential writes/reads is one of them)
7. Finding Messages
Problem: I want to find a specific MEASUREMENT by its NUMBER
It would be a pain to find a MEASUREMENT by going down the NUMBERED LIST, checking every MEASUREMENT one by one if it has the correct NUMBER
I want to go directly to the correct NUMBER
But I can't go directly to the correct NUMBER just by multiplying the NUMBER by some fixed length, because the MEASUREMENTS are all of different types and have different lengths
What I should've done is, as I was putting each MEASUREMENT in the NUMBERED LIST (log file), I should've also written down the starting and ending locations in a notepad (offsets file)
This would allow me to lookup the physical location of a NUMBER in the NUMBERED LIST, and go directly to it
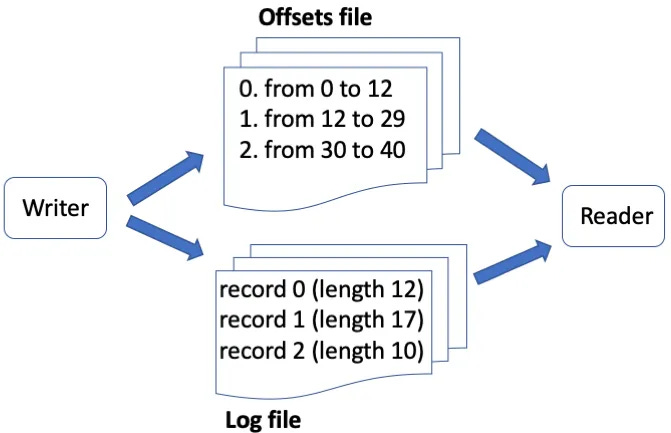
(If you're interested in where the log files are stored, find the server.properties file in kafka/configs and find the directory specified in log.dirs)
8. Finding Messages, Continued
Problem: I want to find a specific MEASUREMENT by its TIMESTAMP
Because I am an engineer, I realise this is easier than it looks
Because I am already organising the MEASUREMENTS by NUMBERS
And a TIMESTAMP is just a bigger NUMBER
A NUMBER orders the MEASUREMENTS relative to each other
A TIMESTAMP also orders the MEASUREMENTS relative to each other, but the difference between the TIMESTAMPS is not always one
For each MEASUREMENT I put in the NUMBERED LIST, I also write the TIMESTAMP and NUMBER in a notepad (time index)
Now if I want to find a specific MEASUREMENT by its TIMESTAMP, I can lookup the corresponding NUMBER, then lookup the corresponding location
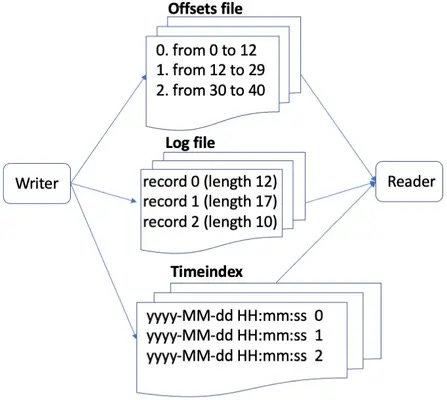
9. Updating Messages
Problem: Oops, the INSTRUMENT's MEASUREMENT was wrong
How do I UPDATE the wrong MEASUREMENT?
If I UPDATE a MEASUREMENT, and its length changes, wouldn't I have to update every offset?
Wouldn't it be a massive, massive PITA?
That's the neat thing, you don't :D
Or, rather, the MEASUREMENT is not the STATE
The MEASUREMENT merely captures the STATE at a particular TIMESTAMP
If the STATE changes, the INSTRUMENT outputs a new MEASUREMENT
Unless a time traveller has messed with a past STATE, the old MEASUREMENT should not change
Input the new MEASUREMENT (id, data) to the MACHINE, and the MACHINE's logic will decide what to do with the MEASUREMENT e.g. insert if new id, update if existing id
I am the in-between part between the INSTRUMENT and the MACHINE, I don't care what happens at the ends
(Incidentally, when it is said that Kafka has high throughput, it means that I, the in-between part, am able to move a large amount of data between the PRODUCERS and the CONSUMERS in a short amount of time. If the PRODUCERS and CONSUMERS are slow as f*ck, and can only produce and consume a trickle of data, Kafka is still a big-*ss pipe with high throughput)
10. Deleting Messages
Problem: Oops, I've filled the room with MEASUREMENTS and now I have no place to put new MEASUREMENTS
How do I DELETE unwanted MEASUREMENTS?
Since I have designed a system with chronological ordering, I can only DELETE chronologically (unless I want to DELETE randomly or even DELETE everything, lol)
Old MEASUREMENTS are less likely to be useful than new MEASUREMENTS, so I want to regularly DELETE old MEASUREMENTS
I cannot DELETE from the NUMBERED LIST, for the same reason I cannot update the NUMBERED LIST
I would have to update all the offsets, and it would be a massive PITA
Instead, I have the galaxy-brain idea to have multiple NUMBERED LISTS (segments) and an offset file and time index for each list
If a NUMBERED LIST is full/has a certain number of MEASUREMENTS, I create a new NUMBERED LIST, resetting the offset
Because there is only ever one active NUMBERED LIST, I can safely DELETE inactive NUMBERED LISTS
And because I put the MEASUREMENTS in the NUMBERED LISTS chronologically, if the last MEASUREMENT in a NUMBERED LIST is older than a certain "expiry date", I can DELETE that NUMBERED LIST as unwanted
(If you're interested in changing the log retention policy, find the server.properties file in kafka/configs, and find log.segment.bytes and log.retention.hours)
Summary So Far and More Optimisations
I'm going to stop with the metaphor of INSTRUMENTS and MACHINES because it's starting to get a little stretched, lol
The key ideas have been covered anyway, which I'm going to summarise as follows:
Kafka is fundamentally a THING to store (transform in TIME) streams of messages (representing either snapshots of STATE or changes in STATE), and to transport (transform in SPACE) messages between producers and consumers
Because streams are high throughput, Kafka must be high throughput
Because Kafka must be high throughput, it must store data on disk, not RAM
Because Kafka is NOT a THING to process (transform in FORM) messages, we can push the structure required to process messages out of the boundaries of Kafka
By dividing a system between productive parts which do useful work (producers and consumers) and speedy parts which transport inputs and outputs between productive parts (Kafka), we can optimise each part for its purpose instead of having a clunky THING which tries and fails to do both
We can't completely push structure out of the Kafka, or we just have a messy PILE we can't find anything in
So we use the simplest structure, a NUMBERED LIST, and organise the events in an append-only log, which allows us to do efficient sequential writes/reads and also efficient direct access with offset/timestamp indices
(Note that we have pushed structure out of Kafka, but not out the system as a whole. Events must still be formatted in the producer and parsed in the consumer, following a model. When we say Kafka does not have a schema, we just mean that the binary representing the formatted data is stored and transported between the producer and consumer without modification by Kafka)
(In Java, we include Kafka and the model as dependencies in the producer/consumer app, and Protobuf as a dependency in the model. We build() and send() the messages in the producer. In the consumer, @KafkaListener automagically polls Kafka and we parseFrom() the new messages. I'll skip the specific implementation details because it's boring I'll leave the implementation details as an exercise for the reader)
(I've also kind of skipped over the fact that append-only logs and tricks to make them efficient are not really new. In the context of RDBMS, write-ahead logs have long been used to persist commands before writing to a database. So if a database crashes, and its state restored from an older backup, the write-ahead log can be used to replay commands to restore the newer state. The clever bit is repurposing a THING that's just a part of an existing system to be the core of a new system)
More Optimisations 1 - Zero Copy
I'm just going to shamelessly copy this diagram from ByteByteGo:
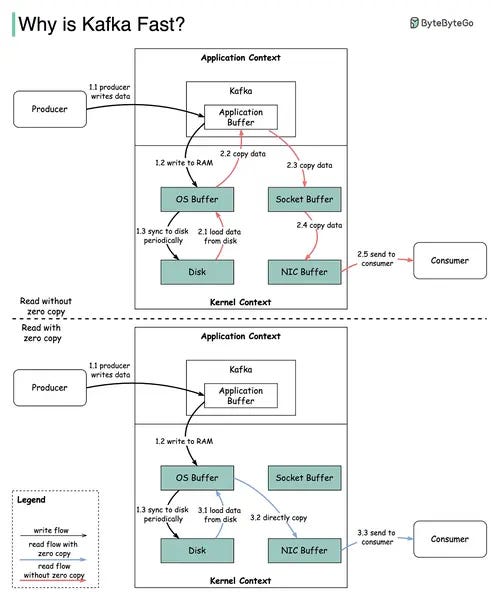
The idea is kind of obvious, but I didn't realise about it until it was pointed out. So was it really that obvious?
Basically after a write to Kafka, the binary data is stored to disk
When a consumer requests that binary data, rather than reading it from disk (kernel context) to Kafka's application memory (application context), before finally writing it to I/O (kernel context)
Kafka just tells the OS to write the binary data to I/O directly from disk
More Optimisations 2 - Batching
Writes and reads can be batched, which reduces network calls
And allows for more efficient compression (since there is more likely to be duplicate data across multiple events than a single event)
Batching works by delaying writes and reads, allowing more events to be sent at one time
But trades off latency for throughput
(The configs for batching are in the producer/consumer app configs for batch.size and linger.ms)
More Optimisations 3 - Commits
Problem: Oops, the consumer died
When we restart the consumer, how do we know which offset to start from?
(In general, we always need to handle two types of failure: an ERROR, where the MACHINE gracefully fails, and a CRASH, where the MACHINE explodes)
We can add a step to have the consumer regularly send a commit message with the latest offset it has processed
When the consumer restarts, it asks Kafka what was its last commit and resumes processing from that offset
(Commit behaviour is configurable. The default configuration is automatic commits at an interval of auto.commit.interval.ms. But automatic commits don't work with asynchronous processing, and so can be disabled with enable.auto.commit. Manual commits must then be made in the code. If no commits have be made before a restart, the consumer follows the reset policy set in auto.offset.reset)
More Optimisations 4 - Topics
Problem: What if we want to differentiate broad types of events? Without going so far as to organise events by schema
Once again, we have the galaxy-brained idea to have multiple NUMBERED LISTS (this will be a recurring theme)
Everything we did so far, let's do all of it again for each type of event, which we shall call topics
Thus each topic will have multiple segments, and each segment will have its own offsets file and time index
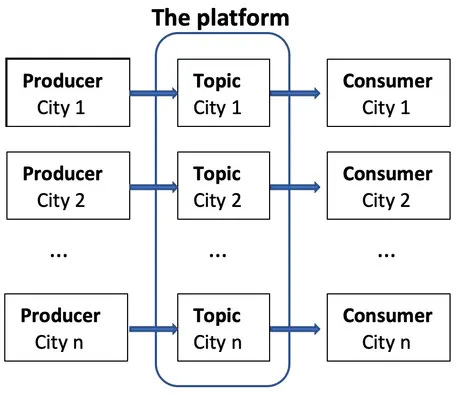
At this point, since our system matches different types of producers with their corresponding types of consumers
We can probably call our system a broker
More Optimisations 5 - Multiple Consumers
This is going to require a new section :)
Multiple Consumers AKA Horizontal Scaling
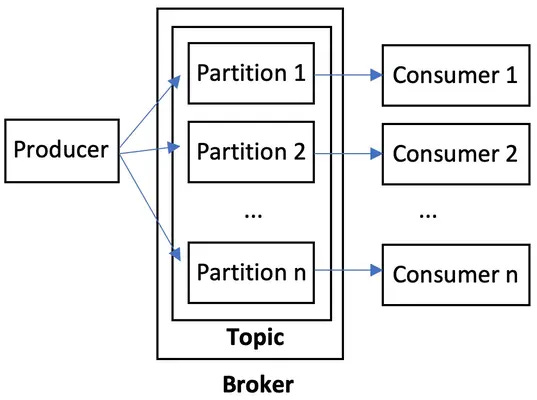
11. Two Consumers, One File
Problem: Producers are producing so much data that one consumer is not able to keep up
Therefore: We add a second consumer
But: Now we need to manage which consumer is reading from where on the same NUMBERED LIST
Therefore: We have the galaxy-brained idea to have multiple NUMBERED LISTS, one for each consumer, so we don't need to manage the offsets, huzzah!
Therefore each topic will have multiple partitions (one for each consumer), and each partition will have
multiple segments, and each segment will have its own offsets file and time index
(The number of partitions is specified when we create a topic. For the details of that and how to update the number of partitions, this seems to be a decent guide
How to change the number of partitions and replicas of a Kafka topic
, though I haven't actually tested it)
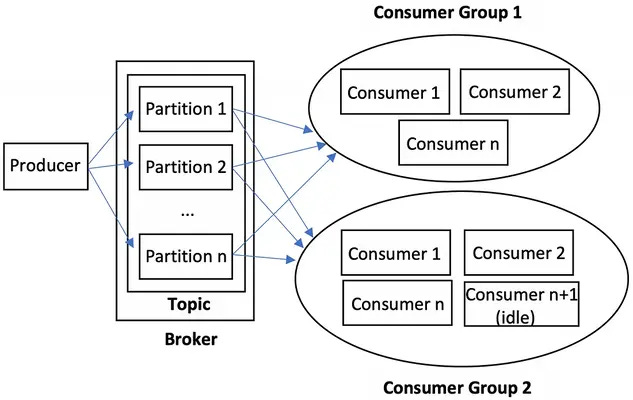
12. Consumer Groups
We now have one partition per consumer, which solves the problem having too many consumers trying to read one file
But: Now we have the opposite problem, of potentially too little consumers trying to read one file (partition)
If one consumer dies, we need to tell a second consumer to process the first consumer's partition, while the first consumer is restarting
By sticking multiple consumers into a consumer group, and tracking which consumers belonging to which groups in the broker
If a consumer fails to send a commit message in a specified period of time, the broker can assume the consumer failed and tell a second consumer in the same group to process the first consumer's partition
13. Multiple Brokers
Resiliency comes from redundancy
What do we do when the broker goes down?
...We add more brokers!
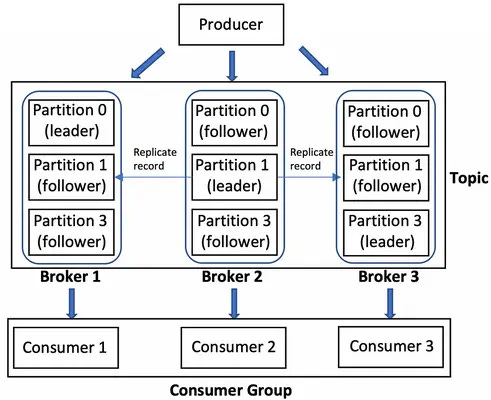
I don't know enough about leadership and replication
Managing leadership and replication could probably be it's own guide, so I'll skip the details
But essentially we clone each partition onto multiple brokers, so that if one broker goes down, the other brokers are still available
To keep the brokers in sync, each instance of a partition can either be a leader or a follower
The leader partition instance replicates messages into follower partition instances
Only when a certain number of followers (quorum) commit replication as successful, does the leader partition instance commit replication as successful
(I'm not entirely sure how Kafka knows which broker contains the leader partition instance, but I've spent way too long on this doc as it is, and I'm too tired to find out :D)
If the leader partition instance goes down, a follower partition instance can be elected as the new leader